更新时间:2024.03.30
支持了目前SOTA的模型:BS Roformer SDR:11.03,支持BS Roformer的UVR只有Windows版本
前言:
网上现存有关UVR5的教程已经过时,UVR5官方也没有一个系统的教程,因此写一个教程填补空缺
UVR官方仓库:https://github.com/Anjok07/ultimatevocalremovergui
下载链接:
Windows(整合CUDA加速和OpenCL加速,N卡A卡I卡核显全部可用,设置方法转到下文主要设置的第二部分):https://github.com/TRvlvr/model_repo/releases/download/uvr_update_patches/UVR_Patch_3_29_24_5_11_BETA_full_roformer.exe
MacOS M芯片(已过时,等待更新):https://github.com/Anjok07/ultimatevocalremovergui/releases/download/v5.6/Ultimate_Vocal_Remover_v5_6_MacOS_arm64.dmg
MacOS Intel芯片(已过时,等待更新):https://github.com/Anjok07/ultimatevocalremovergui/releases/download/v5.6/Ultimate_Vocal_Remover_v5_6_MacOS_x86_64.dmg
由于苹果的严格管控应用程序的安全性,您可能需要按照以下步骤打开UVR:
首先,使用终端运行以下命令,允许应用程序从所有来源运行:
sudo spctl –master-disable
其次,运行以下命令来绕过验证:
sudo xattr -rd com.apple.quarantine /Applications/Ultimate\ Vocal\ Remover.app
Linux:嗯?都用Linux了,用Git拉代码自己部署不是难事吧?欸嘿~
警告:安装路径必须为全英文!!!不推荐修改默认安装路径,否则会有权限问题!!!
主界面:
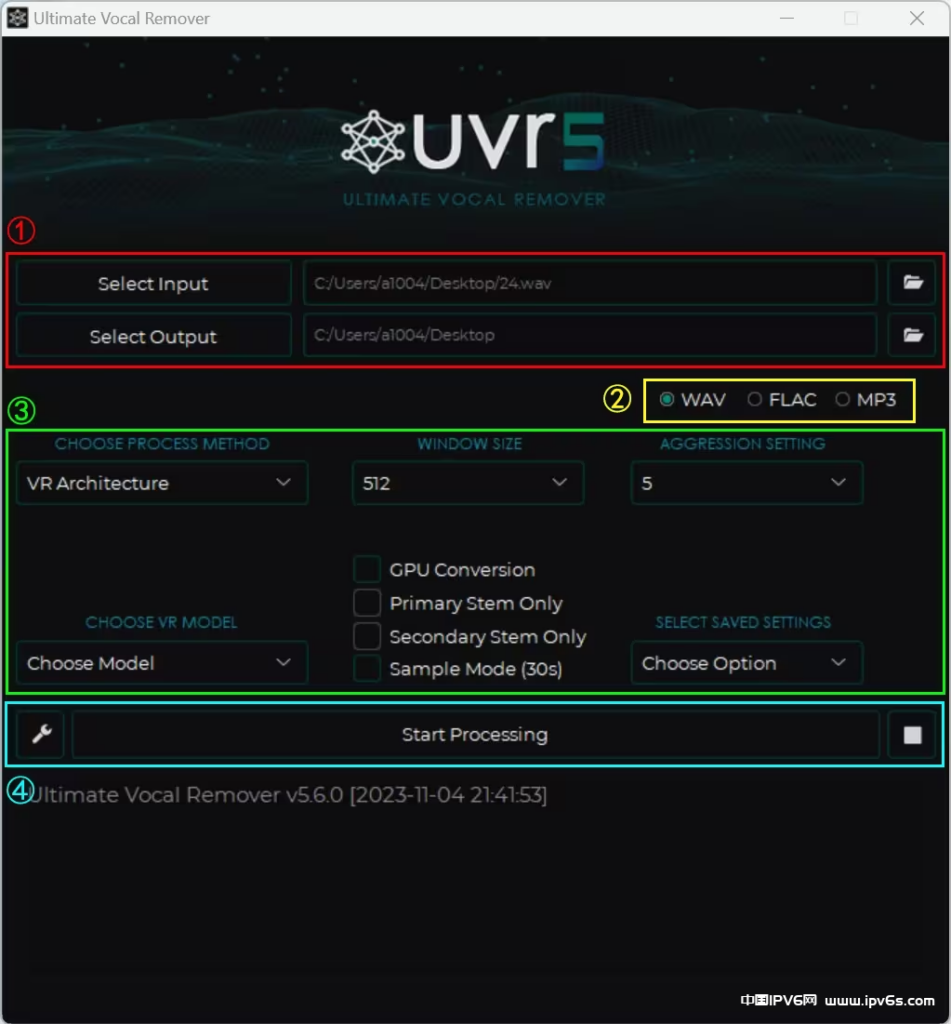

第①部分:
Select Input:导入要处理的音频,可以选择多个音频
Select Output:选择输出音频的目录
第②部分:
选择输出音频的格式:
wav:无损音频,没有被压缩,体积大
flac:无损音频,无损压缩,体积适中
mp3:有损音频,有损压缩,体积小
第③部分:
CHOOSE PROCESS METHOD:选择处理音频的算法
VR Architecture:使用幅度频谱图进行音源分离。
MDX-Net:采用混合频谱网络进行音源分离。
Demucs:利用混合频谱网络进行音源分离。
Ensemble Mode:将多个模型和网络的结果组合以获得最佳结果。
Audio Tools:提供额外的实用工具,以增加便利性。
GPU Conversion:使用显卡加速处理(强烈建议勾选,CPU计算的速度非常慢)
Sample Mode (??s) :只处理??秒的音频,可以预览结果
如果处理算法选择VR Architecture
WINDOW SIZE:选择窗口大小以平衡质量和速度
1024 – 快速但质量较低。
512 – 中等速度和质量。
320 – 需要更长时间,但可能提供更好的质量。(推荐,实际上慢不了多少)
AGGRESSION SETTING:调整主音轨提取的强度
可调范围是[-100, 100],较大的值意味着更深的提取。
通常,对于人声和器乐,将其设置为5。
超过5的值可能会使非人声模型的声音变得混浊。
下面的选项会随着不同的模型发生变化
Vocals Only:只提取人声
Instrumental Only:只提取伴奏
No Echo Only:只输出去掉混响的音频
Echo Only:只输出混响部分的音频
No Noise Only:只输出降噪后的音频
Noise Only:只输出噪声部分的音频
如果处理算法选择MDX-Net
SEGMENT SIZE:调整切片大小
较小的大小消耗较少的资源。
较大的大小消耗更多资源,但可能提供更好的结果。
(默认的256即可,长切片对效果的提升微乎其微)
OVERLAP:控制预测窗口之间的重叠量
较高的值可能会提供更好的结果,但会导致更长的处理时间。
(默认即可,实测没啥提升)
下面的选项会随着不同的模型发生变化
Vocals Only:只提取人声
Instrumental Only:只提取伴奏
No Reverb Only:只输出去掉混响的音频
Reverb Only:只输出混响部分的音频
如果处理算法选择Demucs
CHOOSE STEM(s):选择音轨
Vocals:人声,Bass:贝斯,Drums:鼓,Other:其他乐器
Guitar:吉他,Piano,钢琴(这两项是v4 | htdemucs_6s模型独占)
SEGMENT:调整切片大小
较小的大小消耗较少的资源。
较大的大小消耗更多资源,但可能提供更好的结果。
(默认即可,长切片对效果的提升微乎其微)
如果处理算法选择Ensemble Mode
MAIN STEM PAIR:选择合奏的音轨类型
Vocals/Instrumental:主要音轨:人声,次要音轨:伴奏
Bass/No Bass:主要音轨:贝斯,次要音轨:没有贝斯
Drums/No Drums:主要音轨:鼓,次要音轨:没有鼓
Other/No Other:主要音轨:其他,次要音轨:没有其他
4 Stem Ensemble:汇集所有4音轨Demucs模型并合并所有输出。
Multi-stem Ensemble:”丛林合奏”汇集所有模型并合并相关的输出。(不是很懂QAQ)
ENSEMBLE ALGORITHM:选择用于生成最终输出的合奏算法
例如:Max Spec/Min Spec,斜杠前面的对主要音轨(Primary stem)生效,斜杠后面的对次要音轨(Secondary stem)生效,对于“4音轨合奏(4 Stem Ensemble)”选项,只会显示一个算法。
详细解释:
⚪Max Spec:
产生可能的最高输出。
适用于人声音轨,以获得更丰满的声音,但可能会引入不希望的伪影。
适用于器乐音轨,但请避免在合奏中使用VR Arch模型。
⚪Min Spec:
产生可能的最低输出。
适用于器乐音轨,以获得更清晰的结果。可能会导致“浑浊”的声音。
⚪Average:
将所有结果取平均以生成最终输出。
如果处理算法选择Audio Tools
不做介绍,绝对不是UP懒C= C= C=(っ°Д°;)っ
第④部分:
小扳手🔧:打开设置
Start Processing:开始处理
小方块■:停止处理
主要设置:
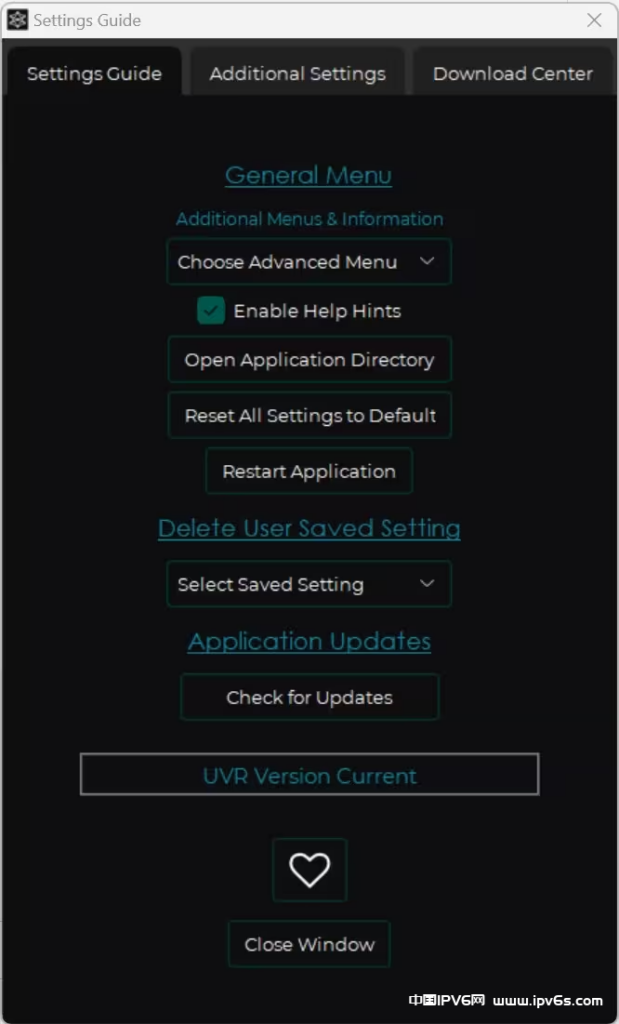
General Menu:
Choose Advanced Menu:见下文的算法设置
Enable Help Hints:打开帮助提示
Open Application Directory:打开软件的安装目录
Reset All Setting to Default:重置所有的设置
Restart Application:重启软件
Delete User Saved Setting:
删除用户保存的预设
Application Updates:
Check for Updates:软件更新
❤:赞助UVR5开发者喵~,赞助UVR5开发者谢谢喵~
Close Window:关闭设置菜单
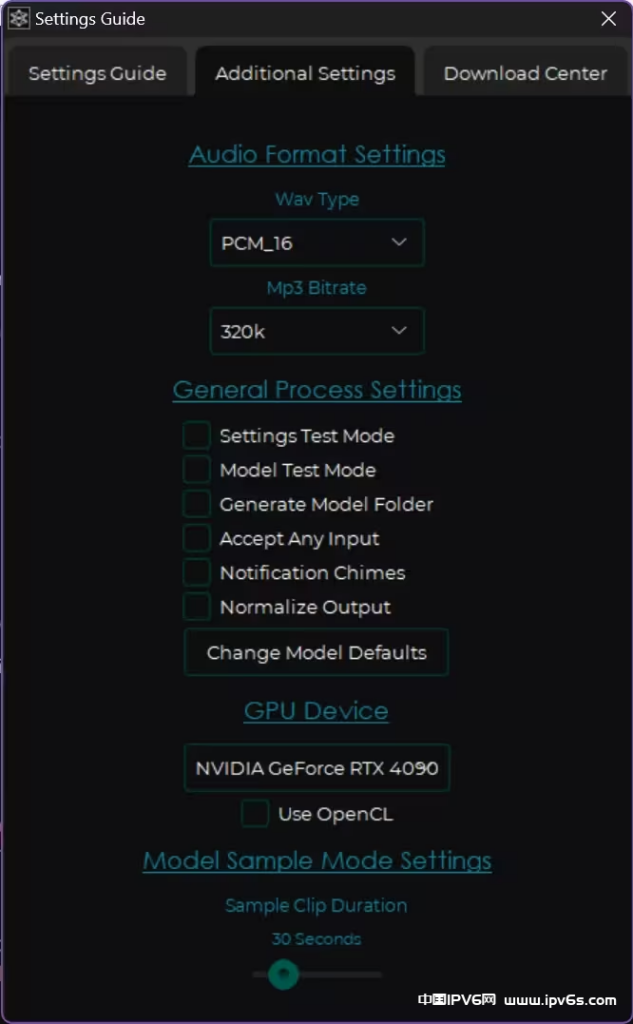
Wav Type:wav的位深度,PCM_16(16bit)完全够用
Mp3 Bitrate:mp3的码率,开320k最高即可
General Process Settings:
Settings Test Mode:将 10 位数字附加到保存的文件名,以避免意外覆盖。
Model Test Mode:将模型名称附加到保存的文件名,以便比较不同模型的效果。
Generate Model Folder:每次转换后,将在导出目录中为输出生成两个新目录。
例子:
─ 导出目录
└── 第一层目录(以模型名称命名)
└── 第二层目录(以曲目名称命名)
└── 输出文件
Accept Any Input:允许导入任何格式的文件,比如word文档(图一乐)
Notification Chimes:处理完成播放提示音
Normalize Output:正则化输出,防止被削波
Change Model Defaults:修改模型的配置文件,勿动!
Vocal Splitter Options:比如分离完人声后再去掉和声,不如直接看文章结尾的连招
GPU Device:选择用哪张显卡加速处理
Use OpenCL:非N卡请打开,然后可以正常使用显卡加速
Model Sample Mode Settings:
Sample Clip Duration:调整预览的时长
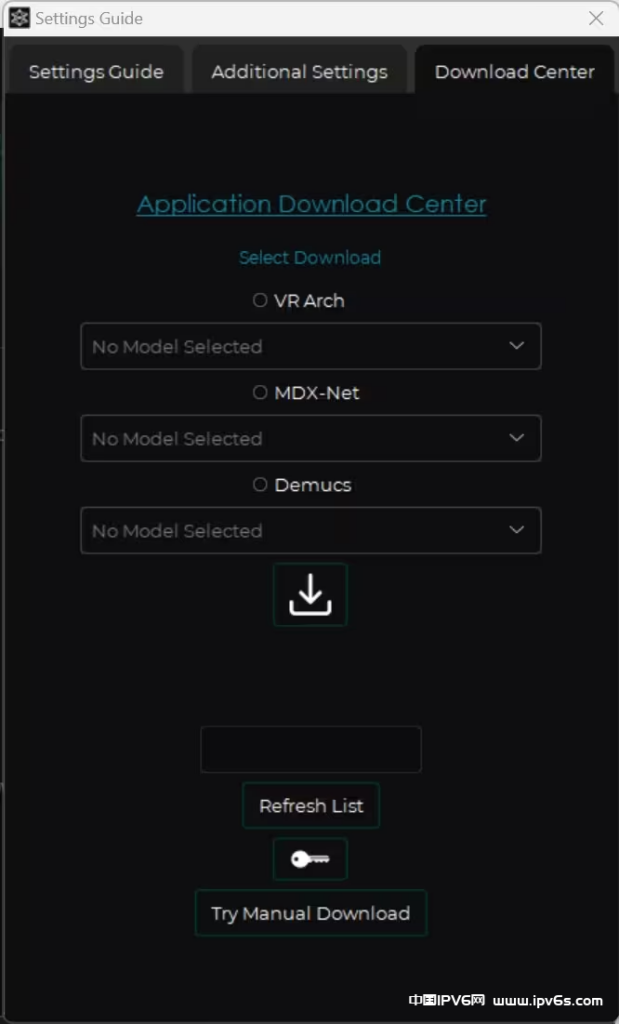
Application Download Center:模型下载中心
需要科学上网,否则会显示No Internet Connection
先选算法,再点下拉框选择模型
算法设置(Advanced VR Options):
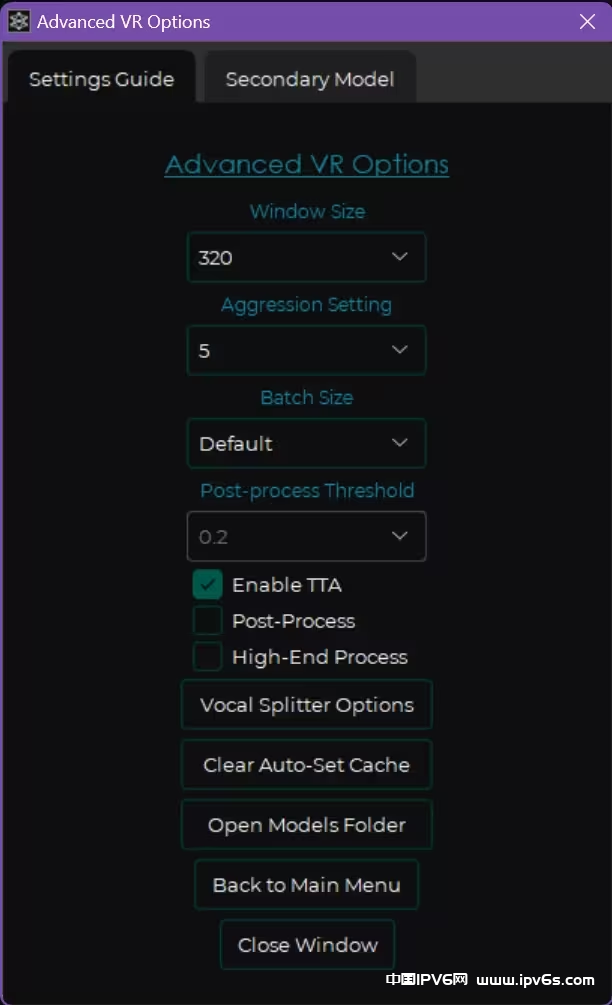
Window Size:见上文,不再赘述
Aggressive Setting:见上文,不再赘述
Batch Size:
较大的值使用更多的显存,加速处理速度
不会对最终的效果产生任何影响
Post-process:
允许用户控制后处理选项的强度。
较高的数值可能会更彻底地去除更多的伪影。然而,可能会切过头,切到正常的地方。
较低的数值限制伪影的去除。
Enable TTA:执行Test-Time-Augmentation(测试时数据增强)来提高分离质量,增加转换消耗的时间。
High-End Process:镜像输出中缺失的频率范围。
最新连招/使用秘技:
X:前置需求
- 确保UVR是最新版本:UVR_Patch_3_29_24_5_11_BETA_full_roformer,macOS要使用bs_roformer请自己拉代码装环境,或者等待安装包制作完成
- 下载模型:https://github.com/TRvlvr/model_repo/releases/download/all_public_uvr_models/model_bs_roformer_ep_368_sdr_12.9628.ckpt
- 把上面下载好的模型放入文件夹:Ultimate Vocal Remover\models\MDX_Net_Models
4.剩余的模型点小扳手🔧,去Download Center里面下载
A:抠干声
- 抠人声【不推荐任何付费以及第三方的模型,UVR的BSRoformer效果就是最好的】:
MDX-Net:BS-Roformer-Viperx-1296选Vocals Only(音源分离领域最强模型,没有之一)
- 去混响【3选1,根据混响的程度选择,没有混响直接跳过】:
VR Architecture:UVR-De-Echo-Normal选No Echo Only(轻度混响)
VR Architecture:UVR-De-Echo-Aggressive选No Echo Only(重度混响)
VR Architecture:UVR-De-Echo-Dereverb选No Reverb Only(遇到鸟之诗这种变态的混响可以用)
- 去和声【4选1,优先尝试前3个,没有和声直接跳过】:
VR Architecture:UVR-BVE-4B_SN-44100-1选Instrumental Only
VR Architecture:5_HP_Karaoke-UVR选Vocals Only (比6激进,有可能会扣过头)
VR Architecture:6_HP_Karaoke-UVR选Vocals Only(没有5激进)
Hit’n’Mix RipX 手动扣出主人声(非必要别用,费时费力,具体看Ripx教程)
B:抠伴奏
MDX-Net:BS-Roformer-Viperx-1296选Instrumental Only(音源分离领域最强模型,没有之一)
C:其他功能
1. 降噪:
VR Architecture:UVR-DeNoise
常见问题(FAQ):
- 炸显存
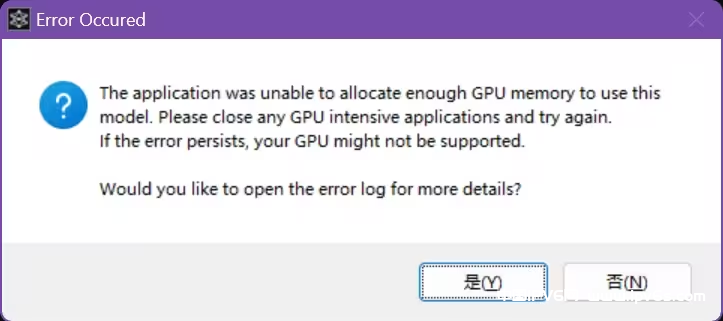
解决方法:调小SEGMENT SIZE / Batch Size / SEGMENT
- 炸内存
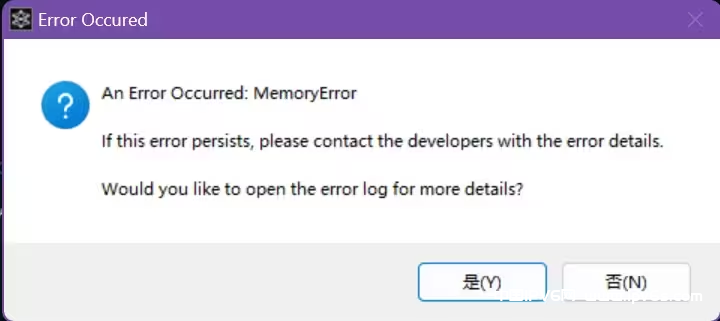
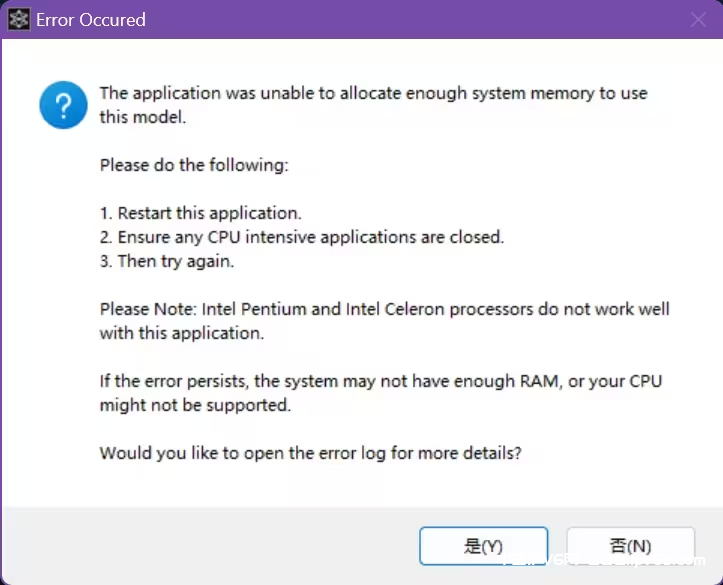
解决方法:把音频切短点
- 处理速度极慢
解决方法:
A. 勾选GPU Conversion
B. 打开任务管理器,检查共享显存的占用是否偏高(正常状态下应该不超过1GB)
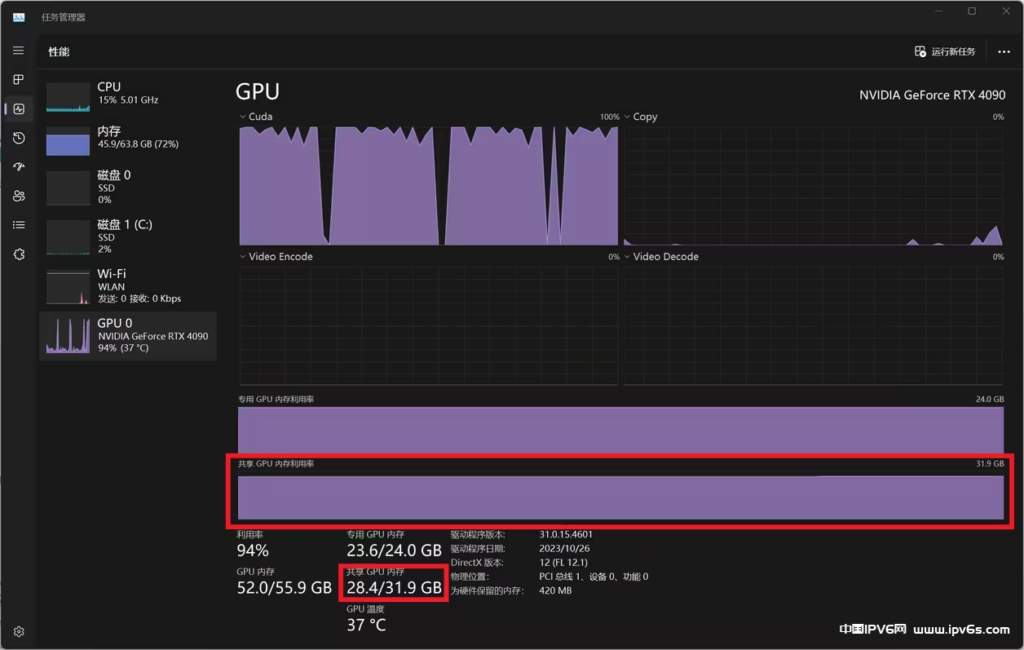
如果共享显存占用正常,更换更强劲的GPU解决问题
如果共享显存占用偏高(如上图)
去NVIDIA官网更新驱动 https://www.nvidia.cn/Download/index.aspx?lang=cn
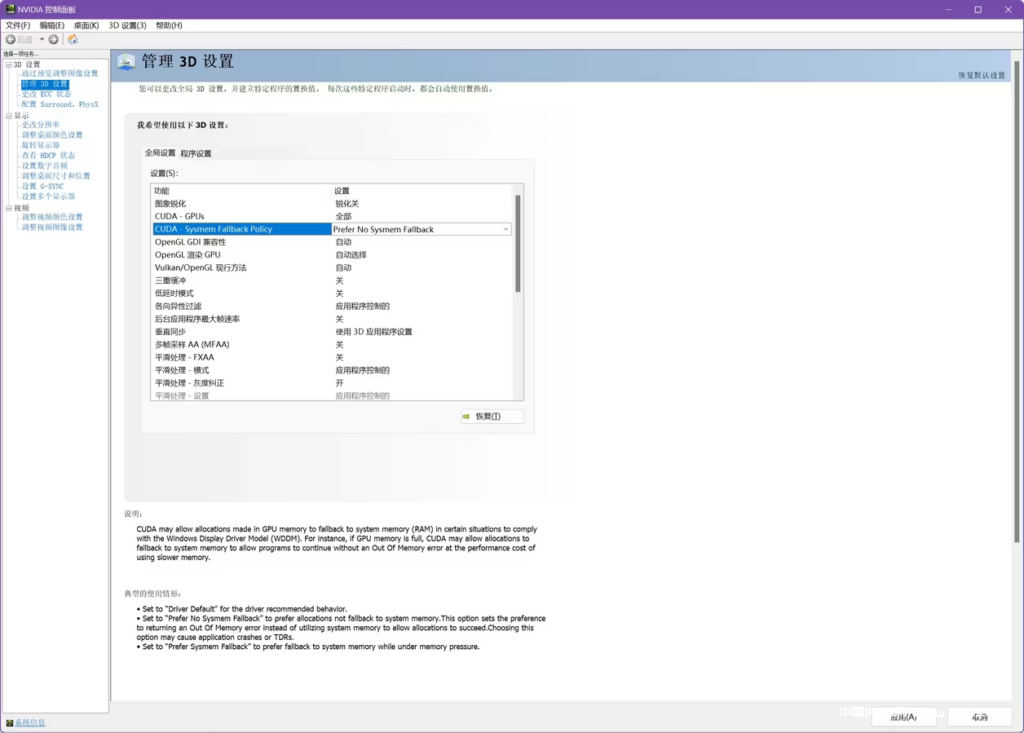
在NVIDIA控制面板内将CUDA – System Fallback Policy改为Prefer No System Fallback,修改完成点右下角的应用,然后重启UVR。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 